We describe the identification of proper names in the Wall Street Journal (WSJ) text. The classification is based on names and their local and global contexts. In general, if a name is referenced again in the following context, the subsequent reference involves a reduced form of the name. This makes them difficult to process. We introduce an efficient computational model of discourse that is used in the identification of unknown proper names and the coreference resolution for proper names. Coreference resolution is based on common patterns of proper names to find different forms they refer to the same thing. The contracted form can be successfully referred to the full name form by a name matching algorithm. The model gains efficiency through reduction of its search space of candidate antecedents. As each new proper name is mentioned, the algorithm checks only the candidate antecedents that contain the first constituent of any newly mentioned name. A further reduction in the search space is achieved by using semantic categories of proper names with pointers to link constituents to those proper names.
As natural language processing (NLP) systems grow more sophisticated, they need larger and more detailed lexicons. The most widespread solution for creating computational lexicons has been the use of machine readable dictionaries. But a dictionary can never be expected to cover proper names one might encounter in a news text. It is desirable to extract information about proper names from a news text in order to make it possible to handle real world text.
Proper names present problems for the automatic understanding of unrestricted text. One problem for processing text is that proper names occur very frequently in news text, and important names are likely to be mentioned many times. In addition, a proper name can occur in variant forms in an article. Yet the classification of unknown names in text is crucial for NLP systems to understand a text, especially news text. Although much of the work being done in identification and categorization is based on the internal structure of names and local contexts, little work has been reported on the discourse properties of names.
An approach to solve unknown name identification relies on the fact that some proper names are accompanied by a name description word, that we call a 'key word.' Key words are words that provide clues to identify preceding or following proper names. For example, titles, degrees, and affiliations are important sources for recognizing personal names. Proper names related to organizations have various key words such as Corp., Inc., Association. These can be definite criteria indicating company or organization. A key word is not always enough to categorize a proper name. For instance, a company name can be designated by a contracted name form without a key word.
Another approach is that the context of the phrases adjacent to the unknown name can be used to provide critical evidence for categorizing a proper name. For instance, new names of people are generally accompanied by appositive phrases (e.g., "Pierre Vinken, 61 years old"), and a city name can be followed by a state or country name (e.g., "Deer Park, N.Y.").
There is little computational work specifically aimed at dealing with coreference for proper names. Most previous work on coreference of proper names used simple pattern matching (for example, Coates-Stephens (1993), Wolinski (1995)). For each unknown proper name, the system checks whether the newly mentioned name appears in the list of proper names seen earlier in the text. This refers to the problem of knowing when an unknown proper name refers back to a previously encountered referent.
The issue is how to constrain the set of all proper names mentioned previously. One of the few algorithms in the literature is described by Mani et al. (1993). This algorithm effectively uses the constraints to eliminate candidates based on normalized names. They introduced normalized names by indexing each proper name by part of a name, and considering only proper names that have the same normalized name. But this approach raises the problem of the choice of a normalized name. Furthermore, if the newly mentioned name is unknown, the algorithm has to consider all proper names mentioned previously.
In this paper, we introduce an efficient coreference resolution model for proper names. The specific aim of our coreference module is to identify unknown names and to unify information describing same thing. It is operating as a component in a natural language understanding system. The major goal of the NLP system is to extract information about proper names from the WSJ to provide lexical and knowledge base entries for proper names.
A typical proper name has a variety of forms that obey a simple rule of contraction [Carroll, 1985; Amsler, 1987; Coates-Stephens, 1993]. This makes recognition of proper names very hard work. A common pattern in news text is to initially give the full form of a name and subsequently use the contracted form. For instance, if a personal name is referenced again in the following context, the subsequent reference involves a reduced name form such as the personal title and surname. Organization names often have their names contracted rather than the full name in the following text. For instance, the company Loews Corp. has its abbreviated form Loews in the remainder of an article. In this case, the local context of the abbreviated form does not enable one to infer its category.
The contracted form can be successfully referred to the full name form by a matching algorithm. For example, the unknown name Mr. Cray can be recognized as Seymour Cray. Conversely, in case of company names reduced names can be recognized from a full name. For example, the company name Cray Computer Inc. may be designated by the words Cray Computer in the remainder of the text.
The name of a person and a company in the same article can share a surname (e.g., Cray Computer Corp., Mr. Cray, Cray). The subsequent reference Cray can not be clearly categorized by simple name matching since it can be matched with both previous names. To solve the problem we use a simple heuristic: When an attempt at an exact match fails with abbreviated forms, the next step is to match against a person in the name list; If a match is not made, the new name can be matched against the rest of the names. In the WSJ, acronyms occur frequently. In general, when an acronym is introduced in a text its full name is given. In some cases, well-known abbreviations may be introduced without complete form in the text such as TV, PC.
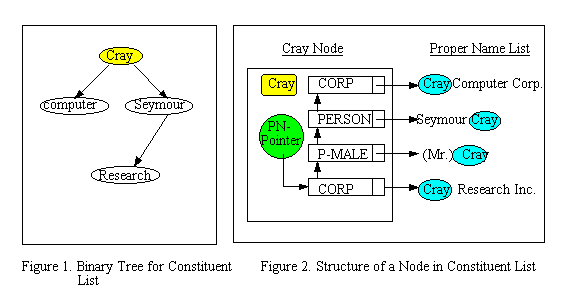
This section considers a simple model of global discourse structure that can be used for identifying the antecedent of proper names, coreference resolution, and acronym matching. The basic idea is that all different name forms seen so far are maintained in a name list, and all names that have a common constituent are referenced by a common constituent node. In order to establish links from a common constituent to all names, a constituent node needs pointers as the number of names. For example, as in Figure 2, the 'Cray' node needs four pointers.
This approach provides an efficient name matching structure because each name in a name list can be accessed efficiently by its name component only, as well as by the character module. For example, for the acronym NIH, its full name (National Institutes of Health) can be accessed by visiting the constituent nodes that begin with the character 'N' with a simple pattern matching. The data structure for corefernce resolution is that there are three different levels of representation: the constituent list, the proper name list, the knowledge base objects.
The proper name list (PN-list) is a list of different forms of proper names
generated from the preceding sentences in an article. Each proper name in the
PN-list points to a unique object that is a frame-like structure. Thus all
variant forms that describe same thing point to a frame. For example, Cray
Computer Corp. and Cray Computer point to the same frame. This
approach enables the various references to be recognized, and their attributes
to be unified.
The basic structure idea is the constituent list (C-list),
which is a list of constituents composing proper names. The C-list is a sequence
of structures corresponding to the unique constituents (except keywords and
function words) of proper names in the prior local or global contexts. For
example, the first mention of 'Cray Computer Corp.' evokes the two terms 'Cray'
and 'Computer' for the C-list.
We can organize the constituents of proper names to cope efficiently with a
list of arbitrary constituents. The approach is to keep the set of unique
constituents seen so far sorted at all times, by using a binary tree. We can
construct a typical binary tree for the constituent list, as in Figure 1, which
shows the entire space of constituents for the proper names in Figure 2. The
tree contains one node per distinct constituent; each node contains a
constituent and a linked list structure called PN-pointers as shown in Figure 2.
A PN-pointer structure in a constituent node contains a semantic type and a
pointer, and this structure is automatically generated when a new name form is
introduced. A pointer is used to establish a link from a constituent to each
different form of proper name that contains a constituent that also appears in
the node. The semantic type of a PN-pointer represents the semantic category of
proper names. For instance, the ABBR represents a contracted form, and an
unknown name is represented by UN.
The reduction in search space is achieved
by using the C-list. Furthermore, if the semantic type of a newly mentioned name
is recognized, further reduction is achieved by using semantic type matching.
For instance, "(Mr.) Cray" can be found in the PN-list by accessing PN-pointers
whose semantic type is P-MALE indicating person whose gender is male.
The
PN-pointers in each node are automatically sorted historically. The most
recently introduced PN-pointer is stored at the front of the linked list. This
structure enables us to implement a recency constraint (Allen, 1995). For
example, to match names for Cray Research, we search the C-list for the
constituent Cray that is the first component of the name. In this case,
the first PN-pointer, pointing Cray Research Inc., is tested.
The initial list of candidates is provided by the C-list, and each candidate has a semantic type. Thus we can consider only proper names pointed to by PN-pointers rather than all proper names. This process is defined more precisely by the following coreference algorithm:
If a match is not made, the algorithm returns no match. This matching procedure can lead to one of the three possible cases:
When a match is made (exact or partial), the system unifies information associated with the newly mentioned name with attributes of antecedent at the frame of antecedent. Whenever a new form of a proper name is introduced (no match or partial match), the name is added to the PN-list and its constituents are generated for the C-list entry by the constituent construction algorithm:
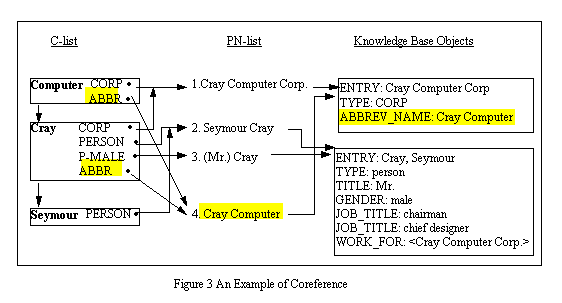
Figure 3 shows an example of coreference. Assume the number before proper names in the PN-list indicates the order mentioned in the given context, and the first three names have been processed. For the next name, Cray Computer, a partial match is made with Cray Computer Corp. by visiting the 'Cray' node in the C-list. Two PN-pointers whose semantic type is ABBR are created at the 'Cray' and 'Computer' nodes in the C-list, and they are linked to Cray Computer, while the coanchoring of the new name Cray Computer to the frame is established. In the frame a new attribute, ABBREV_NAME, is added.
We have discussed three basic techniques for the identification of unknown
proper names. Most work on coreference for proper names has used simple pattern
matching by exploring all the names mentioned so far. We introduce an efficient
model of coreference resolution for proper names. We have used two basic data
structures, the PN-list and the C-list, to provide an efficient name matching
mechanism that can be accessed by a name component as well as the character
module. This approach reduces the search space for candidate names.
Our
coreference model, implemented for proper names, has been run on the WSJ text.
The system handles various name patterns such as contracted forms and acronyms.
Allen, James, 1995. Natural language Understanding, The Benjamin/Cummings Publishing Company, Redwood City, CA.
Amsler, Robert, 1987. words and Worlds. Proceedings of the Third Workshop on Theoretical Issues in Natural language Processing (TINLAP3), New Mexico State University at Las Cruces, NM, January 7-9, 1987, 11-15.
Carroll, James M., 1985. What's in a Name?, W.H. Freeman and Company, New York, 1985.
Coates-Stephens, Sam, 1993. The Analysis and Acquisition of Proper Names for the Understanding of Free Text. Computers and Humanities, 1993, Vol. 26, Kluwer Academic Publishers, Hingham, MA, 441-456.
Cowie, Jim and Wendy Lehnert, 1996. Information Extraction, Communications of the ACM, January 1996, Vol. 39, No. 1, pp. 80-91.
Mani, Inderjeet, T. Richard Macmillan, Susann Luperfoy, Elaine P. Lusher, Sharon J. Laskowski, 1993. Identifying Unknown Proper Names in Newswire Text. In Branimir Boguraev, James Pustejovsky (eds.) Proceedings of the ACL SIG Workshop on Acquisition of Lexical Knowledge from Text. Ohio State University, Columbus, Ohio, 21 June 1993, 44-53.
Wolinski, Francis, Frantz Vichot, Bruno Dillet, 1995. Automatic Processing of Proper Names in Texts, Proceedings of the Seventh Conference of the European Chapter of the Association for Computational Linguistics, March 27-31, 1995, University of College Dublin, Belfield, Dublin, Ireland, 23-30.