This work has been motivated by my desire to understand human language learning ability and to build programs that can understand language. Therefore the design decisions were given with a view towards extraction of meaning. Representing syntactic relations between words directly is a consequence of having this goal. The primitive operation in the standard phrase-structure formalism is to group words or phrases to form higher order constituents. Meaningful relations between words is an indirect outcome of the grouping process. The primitive operation in my work is finding meaningful relations between words:
![\begin{figure}\centering
\par\fbox{
\parbox{4.5in}{
\vspace*{10pt}\hspace{1pt}...
...)()][(washington)()]] [[4 5 0 ()]] mydiagram}}
\vspace{11pt}}}\par\end{figure}](img65.gif)
The likelihood of two words being related is defined as lexical attraction. Knowledge of lexical attraction between words play an important role in both language processing and acquisition. I developed a language program in which lexical attraction is the only explicitly represented linguistic knowledge. In contrast to other work in language processing or acquisition, my program does not have a grammar or a lexicon with word categories. Chapter 3 formalizes lexical attraction within the context of information theory:
![\begin{figure}\par\begin{center}
\fbox{\parbox{4.5in}{
\vspace*{10pt}
\mbox{\v...
...12)]] mydiagram}}
\vspace{11pt}}
\vspace*{20pt}
}}\end{center}\par\end{figure}](img66.gif)
The program starts processing raw language input with no initial knowledge. It is able to discover more meaningful relations between words as it processes more language. The bootstrapping is achieved by the interdigitation of learning and processing. The processor uses the regularities detected by the learner to impose structure on the input. This structure enables the learner to detect higher level regularities which are difficult to see in raw input. Chapter 4 discusses the bootstrapping process:
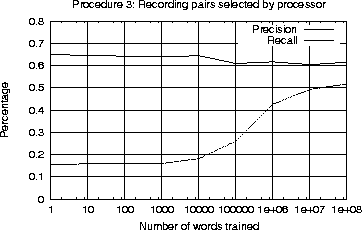
Starting with no knowledge and training on raw data, the program was able to achieve 60% precision and 50% recall in finding relations between content-words. This is a significant result as previous work in unsupervised language acquisition demonstrated little improvement when started with zero knowledge.
The key insights that differentiate my approach from others are:
This work has potential applications in semantic categorization and information extraction. More importantly it may shed light on how humans are able to learn language from raw data and easily understand syntactically ambiguous sentences.