This chapter presents snapshots from the learning process. The underlying theory and the algorithm follows in the next chapters. The examples in this chapter were chosen to illustrate the handling of various linguistic phenomena. Formal performance results and a critical evaluation of the program's shortcomings are given in Chapter 4.
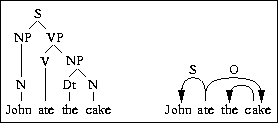
The syntax is represented in a dependency formalism. Figure 2.1 contrasts the phrase structure and the dependency representations of a sentence. The phrase structure representation is based on forming higher order units by combining words or phrases. The dependency representation is based on explicit representation of the relationships between individual words. Chapter 3 gives a more formal definition.
For the examples in this chapter, the program was trained on a corpus of Associated Press Newswire material2.1. It was stopped at various points during training and given the example sentences for processing.
Most of the links in Figure 1.4 spanned a few words. Figure 2.2 shows that the program is also capable of handling longer distance relations. The sentence has a long noun phrase headed by the noun cause. It is this cause which is not given, a link that spans the length of the sentence.
At 1,000 words, you see again that nothing much interesting is discovered. At 100,000 words, the program is able to relate the cause to the death but longer distance relations are still missing. After ten million words of training, the attraction between the word cause and the word given is discovered and the correct link is created.
One of the most difficult problems for non-lexicalized language systems is to analyze the structure of a complex noun phrase. The noun phrase ``the New York Stock Exchange Composite Index'' in Figure 2.3 turns into ``determiner adjective noun noun noun adjective noun'' when seen as just parts of speech. The parts of speech do not give enough information to assign a meaningful structure to the phrase.
My program collects information about individual words but it has no concept of parts of speech. It is able to discover the structure of the complex noun phrase in Figure 2.3 because pieces of that noun phrase are repetitively used elsewhere.
At 10,000 words, it discovers the group ``new york''. At 100,000 words, it discovers ``stock exchange''. At a million words it discovers ``composite index''. And finally at ten million words it figures out the correct relations between these pieces.
I have argued in Chapter 1 that we need semantic judgments to interpret syntactically ambiguous sentences. Specifically what we need is information about the likelihood of various relations between words, i.e. lexical attraction information. This section presents several examples of syntactic ambiguity and demonstrate how lexical attraction information helps to resolve the ambiguity.
Figure 2.4 shows a prepositional phrase attachment problem. The sentence ends with three prepositional phrases, each starting with the word ``in''. Syntax does not uniquely determine where they should be attached. At 100,000 words, the program still has not decided on the final attachment. Somewhere between 100,000 words and 1,000,000 words, it learns enough to relate died to clashes, clashes to west, and september to died. Note that ``died in the west'' and ``clashes in september'' are also meaningful phrases. However the links discovered by the program had stronger attraction.
Figure 2.5 illustrates a common type of ambiguity
related to the of-phrase. The English preposition of is
particularly ambiguous in its semantic function [Quirk et al., 1985]. It
can be used in a function similar to that of the genitive (the
gravity of the earth ![]() the earth's gravity), or in partitive
constructions (bottle of wine) among others.
the earth's gravity), or in partitive
constructions (bottle of wine) among others.
The two sentences in Figure 2.5 are syntactically identical. They both have the same phrase ``number of people'' as subject. In the first one it is the people who are doing the protesting, whereas in the second one, it is the number which is increasing. After five million words of training, the lexical attraction information becomes sufficient to find the correct subject.
Figure 2.6 presents our final example, which is analogous to Sentence (1) from the previous chapter. I replaced some words with ones that were more frequent in the corpus. The sentence is ambiguous as to who is doing the flying. The program is able to link pilot with flying in the first case and airplane with flying in the second case based on lexical attraction.
![\begin{figure}
\centering
\fbox{
\parbox{5.8in}{
$N=1,000$\par {\smallskip \pari...
... 0 ()][7 9 1 ()][2 9 2 ()][2 10 3 ()][10 11 0 ()]] [0 ] diagram}}
}}\end{figure}](img8.gif)
![\begin{figure}
\centering
\fbox{
\parbox{5.8in}{
$N=10,000$\par {\smallskip \par...
... 7 0 ()][5 7 1 ()][1 7 2 ()][7 8 0 ()][9 10 0 ()]] [0 ] diagram}}
}}\end{figure}](img9.gif)
![\begin{figure}
\centering
\fbox{
\parbox{5.8in}{
$N=100,000$\par {\smallskip \pa...
...()][3 11 3 ()][0 11 4 ()][11 12 0 ()][12 13 0 ()]] [0 ] diagram}}
}}\end{figure}](img10.gif)
![\begin{figure}
\centering
\fbox{
\parbox{5.8in}{
$N=5,000,000$\par {\smallskip \...
...1 2 0 ()][2 3 0 ()][2 4 1 ()][2 5 2 ()][6 7 0 ()]] [0 ] diagram}}
}}\end{figure}](img12.gif)
![\begin{figure}
\centering
\fbox{
\parbox{5.8in}{
$N=10,000,000$\par {\smallskip ...
... 6 0 ()][6 7 0 ()][6 8 1 ()][8 9 0 ()][9 10 0 ()]] [0 ] diagram}}
}}\end{figure}](img13.gif)