This work has been motivated by a desire to explain language learning on one hand and to build programs that can understand language on the other. I believe these two goals are very much intertwined. As with many other areas of human intelligence, language proved not to be amenable to small models and simple rule systems. Unlocking the secrets of learning language from raw data will open up the path to robust natural language understanding.
I believe what makes humans good learners is not sophisticated learning algorithms but having the right representations. Evolution has provided us with cognitive transducers that make the relevant features of the input explicit. The representational primitives for language seems to be the linguistic relations like subject-verb, verb-object. The standard phrase-structure formalism only indirectly represents such relations as side-effects of the constituent-grouping process. I adopted a formalism which takes relations between individual words as basic primitives. Lexical attraction gives the likelihood of such relations. I built a language program in which the only explicitly represented linguistic knowledge is lexical attraction. It has no grammar or a lexicon with parts of speech.
My program does not have different stages of learning and processing. It learns while processing and gets better as it is presented with more input. This makes it possible to have a feedback loop between the learner and the processor. The regularities detected by the learner enable the processor to assign structure to the input. The structure assigned to the input enables the learner to detect higher level regularities. Starting with no initial knowledge, and seeing only raw text input, the program is able to bootstrap its acquisition and show significant improvement in identifying meaningful relations between words.
The first section presents lexical attraction knowledge as a solution to the problems of language acquisition and syntactic disambiguation. The second section describes the bootstrapping procedure in more detail. The third section presents snapshots from the learning process. Chapter 2 gives more examples of learning. Chapter 3 explains the computational, mathematical and linguistic foundations of the lexical attraction models. Chapter 4 describes the program and its results in more detail. Chapter 5 summarizes the contributions of this work.
Lexical attraction is the measure of affinity between words, i.e. the likelihood that two words will be related in a given sentence. Chapter 3 gives a more formal definition. The main premise of this thesis is that knowledge of lexical attraction is central to both language understanding and acquisition. The questions addressed in this thesis are how to formalize, acquire and use the lexical attraction knowledge. This section argues that language acquisition and syntactic disambiguation are similar problems, and knowledge of lexical attraction is a powerful tool that can be used to solve both of them.
Syntax and semantics play complementary roles in language understanding. In order to understand language one needs to identify the relations between the words in a given sentence. In some cases, these relations may be obvious from the meanings of the words. In others, the syntactic markers and the relative positions of the words may provide the necessary information. Consider the following examples:
(1) I saw the Statue of Liberty flying over New York.
(2) I hit the boy with the girl with long hair with a hammer with vengeance.
In sentence (1) either the subject or the object may be doing the flying. The common interpretation is that I saw the Statue of Liberty while I was flying over New York. If the sentence was ``I saw the airplane flying over New York'', most people would attribute flying to the airplane instead. The two sentences are syntactically similar but the decision can be made based on which words are more likely to be related.
Sentence (2) ends with four prepositional phrases. Each of these phrases can potentially modify the subject, the verb, the object, or the noun of a previous prepositional phrase, subject to certain constraints discussed in Chapter 3. In other words, syntax leaves the question of which words are related in this sentence mostly open. The reader decides based on the likelihood of potential relations.
(3) Colorless green ideas sleep furiously.
In contrast, sentence (3) is a classical example used to illustrate the independence of grammaticality from meaningfulness1.1. Even though none of the words in this sentence go together in a meaningful way, we can nevertheless tell their relations from syntactic clues.
These examples illustrate that syntax and semantics independently constrain the possible interpretations of a sentence. Even though there are cases where either syntax or semantics alone is enough to get a unique interpretation, in general we need both. What we need from semantics in particular is the likelihood of various relations between words.
Children start mapping words to concepts before they have a full grasp of syntax. At that stage, the problem facing the child is not unlike the disambiguation problem in sentences like (1) and (2). In both cases, the listener is trying to identify the relations between the words in a sentence and syntax does not help. In the case of the child, syntactic rules are not yet known. In the case of the ambiguous sentences, syntactic rules cannot differentiate between various possible interpretations.
Similar problems call for similar solutions. Just as we are able to interpret ambiguous sentences relying on the likelihood of potential relations, the child can interpret a sentence with unknown syntax the same way.
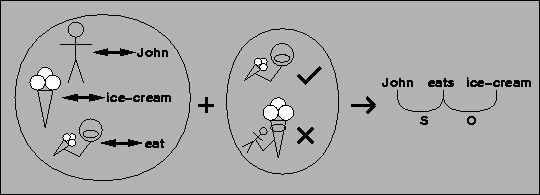
Figure 1.1 illustrates this language acquisition path. Exposure to language input teaches the child which words map to which concepts. Experience with the world teaches him the likelihood of certain relations between concepts. With this knowledge, it becomes possible to identify certain linguistic relations in a sentence before a complete syntactic analysis is possible.
With the pre-syntax identification of linguistic relations, syntactic acquisition can be bootstrapped. In the sentence ``John eats ice-cream'', John is the subject of eating and ice-cream is the object. English relies on the SVO word order to identify these roles. Other languages may have different word ordering or use other syntactic markers. Once the child identifies the subject and the object semantically, he may be able to learn what syntactic rule his particular language uses. Later, using such syntactic rules, the child can identify less obvious relations as in sentence (3) or guess the meanings of unknown words based on their syntactic role.
In language acquisition, as in disambiguation, knowing how likely two words are related is of central importance. This knowledge is formalized with the concept of lexical attraction.
Learning and encoding world experience with computers has turned out to be a challenging problem. Current common sense reasoning systems are still in primitive stages. This suggests the alternative of using large corpora to gather information about the likelihood of certain relations between words.
However, using large corpora presents the following chicken-and-egg problem. In order to gather information about the likelihood that two words will be related, one first has to be able to detect that they are related. But this requires knowing syntax, which is what we were trying to learn in the first place.
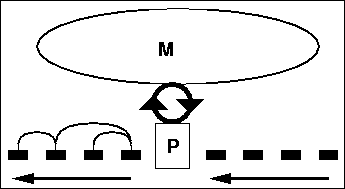
To get out of this loop, the learning program needs a bootstrapping mechanism. The key to bootstrapping lies in interdigitating learning and processing. Figure 1.2 illustrates this feedback loop. With no initial knowledge of syntax, the processor P starts making inaccurate analyses and memory M starts building crude lexical attraction knowledge based on them. This knowledge eventually helps the processor detect relations more accurately, which results in better quality lexical attraction knowledge in the memory.
Based on this idea, I built a language learning program that bootstraps with no initial knowledge, reads examples of free text, and learns to discover linguistic relations that can form a basis for language understanding.
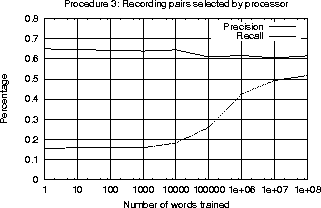
The program was evaluated using its accuracy in relations between content-words, e.g. nouns, verbs, adjectives and adverbs. The accuracy was measured using precision and recall. The precision is defined as the percentage of relations found by the program that were correct. The recall is defined as the percentage of correct relations that were found by the program. The program was able to achieve 60% precision and 50% recall. Previous work in unsupervised language acquisition showed little improvement when started with zero knowledge. Figure 1.3 shows the improvement my program shows. Detailed results are given in Chapter 4.
Figure 1.4 shows how the program gradually discovers the correct relations in a simple sentence. N denotes the number of words used for training. All words are lowercased. The symbol * marks the beginning and the end of the sentence. The links are undirected. In Chapter 3, I show that the directions of the links are immaterial for the training process.
Before training (N=0) the program has no information and no links are found. At 1,000 words the program has discovered that a period usually ends the sentence and the word these frequently starts one. At 10,000 words, not much has changed. The frequent collocation money for is discovered. More words link to the left * marker. Notice that want, for example, almost never starts a sentence. It is linked to the left * marker because as more links are formed, the program is able to see longer distance correlations.
The lack of meaningful links up to this point can be explained by the
nature of word frequencies. A typical word in English has a frequency
in the range of 1/10,000 to 1/50,000. A good word frequency
formula based on Zipf's law is
![]() where n is the rank
of the word [Zipf, 1949,Shannon, 1951]. This means that after 10,000
words of training, the program has seen most words only once or twice,
not enough to determine their correlations.
where n is the rank
of the word [Zipf, 1949,Shannon, 1951]. This means that after 10,000
words of training, the program has seen most words only once or twice,
not enough to determine their correlations.
At 100,000 words, the program discovers more interesting links. The word people is related to want, these modifies people, and also modifies want. The link between more and for is a result of having seen many instances of more X for Y.
The reason for many links to the word for at N=100,000deserves some explanation. We can separate all English words into two
rough classes called function words and content words. Function words
include closed class words, usually of grammatical function, such as
prepositions, conjunctions, and auxiliary verbs. Content words
include words bearing actual semantic content, such as nouns, verbs,
adjectives, and adverbs. Function words are typically much more
frequent. The most frequent function word the is seen ![]() of
the time, others typically are in the 1/100 to 1/1,000 range.
This means that the program first discovers
function-word-function-word links, like the one between period and *.
Next, the function-word-content-word links are discovered, like the
ones connecting for. The content-word-content-word links are
discovered much later.
of
the time, others typically are in the 1/100 to 1/1,000 range.
This means that the program first discovers
function-word-function-word links, like the one between period and *.
Next, the function-word-content-word links are discovered, like the
ones connecting for. The content-word-content-word links are
discovered much later.
After 1,000,000 words of training, the program is able to discover the correct links for this sentence. The verb is connected to the subject and the object. The modifiers are connected to their heads. The words money and education related by the preposition for are linked together.
![\begin{figure}
\fbox{
\parbox{5.8in}{
$N=0$\par \vbox to 20bp{\vss\special{''[(*...
... 2 ()][7 8 0 ()][7 9 1 ()][9 10 0 ()][10 11 0 ()]] [0 ] diagram}}
}}\end{figure}](img4.gif)